
Bridging the Language Gap: Evaluating Text Data Pre-processing and Classification Techniques in Urdu Sentiment Analysis
DOI:
https://doi.org/10.62019/abbdm.v4i02.183Abstract
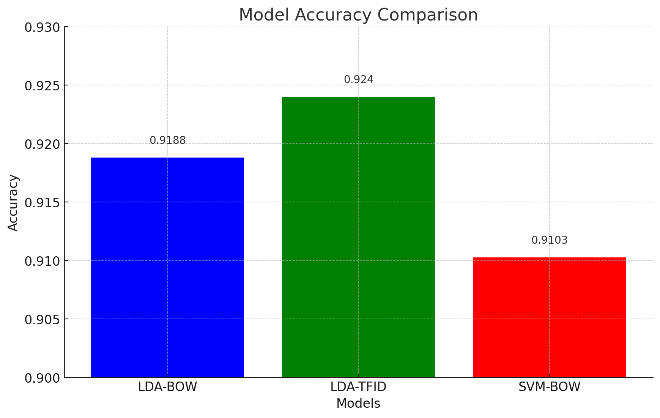
The advancement of the internet and rapid growth in social media platforms such as Facebook, X , Instagram and others which made it possible for information on review on goods, reaction on events, services from experts, and political beliefs to be easily and globally shared within no time. Due to this fast propagation of information may have both positive and negative impact on thinking and ability to take decision on a particular event or anything related. Due to the generation of such a huge number of date and while the volume of studies directed on slant investigation is quickly extending, these examinations for the most part address English language concerns. But the English the not the only language by which data is got propagated but other such as Urdu, Farsi, Hindi, Pasto, branch etc. The main goal of this research study is to critically assess the data related to Urdu and the Urdu sentiment analysis's progress and problems and present solutions. After critically reviewing the literature and related work following two research directions are identified in accordance with our study— the first one is text pre-processing and the other is sentiment classification. Here, we had the opportunity to describe the progress that has been made in this research field. The pre-processing steps include Tokenisation, stop words removal, word segmentation, text cleaning, transforming into numeric vectors and others then applying machine learning models i.e. regression and SVM. Result is compared out for each of the model use. After thorough investigation, the following results demonstrated that the LDA-TFID model achieved the highest accuracy at 0.923977 as compared to LDA-BOW and SVM-BOW and also outperforming both LDA-BOW and SVM-BOW in term of efficiency and accuracy. This indicates the effectiveness of TF-IDF in enhancing model performance for Urdu sentiment analysis.
Downloads
Published
Issue
Section
License
Copyright (c) 2024 Mohammad Bilal, Mahira Zainab, M Ramzan Shahid Khan, Ali Raza, Sonia Shehzadi, Faiz-ur- Rehman, Asif Raza

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
How to Cite




