
Analysis of Deep Learning Models on VQA(Toloka)Dataset
DOI:
https://doi.org/10.62019/1h3r5m91Keywords:
Toloka VQA, IoU, Visual Question Answering, Object detection.Abstract
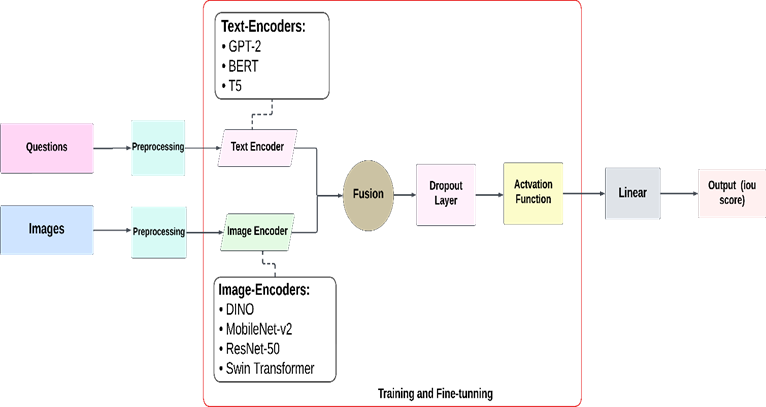
Visual Question Answering (VQA) is a recent task at the intersection of computer vision and natural language processing. In this task, instead of giving phrase images, machines will go on to learn and interpret them. It is also their job to answer any question in turn. Instead of the usual "Images ten questions", it relies on phrases reversed in order and asks unrelated questions about pictures. One way which VQA current challenges itself picks up new trends is with this issue for the model to predict an image and where provide bounding box as output, given input image together with a questioning on natural language sentence. Unlike traditional VQA tasks, where the model outputs a textual answer, this challenge presents a more complex scenario by not explicitly mentioning the object name in the question, making it more demanding than typical VQA and visual grounding tasks. A comparative analysis is performed using the Toloka VQA challenge dataset, which has seen limited exploration in existing research. Our findings show that a combination of the DINO and T5 models achieved a high Intersection over Union (IoU) score of 0.67, demonstrating its effectiveness in this unique context. Similarly, the BERT combined with Swin Transformer model yielded a competitive IoU score of 0.60. In contrast, models like MobileNet-v2 and GPT with ResNet-50 + BERT struggled, displaying lower IoU values and highlighting the challenges posed by this dataset.
Downloads
Published
Issue
Section
License
Copyright (c) 2025 Fariha Shoukat , Muhammad Naveed, Nazia Azim, Arooj Imtiaz Imtiaz

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
How to Cite




